最近看Divergence-Free SPH (DFSPH) 的论文时看到了一个有趣的性能优化方法——Lookup tables。
Smoothed Particle Hydrodynamics (SPH)方法会频繁的涉及Kernel的计算。Kernel可以理解为一种加权平均的函数,越相近的部分会获得更高的权值,以此就可以使用附近粒子的平均属性估算空间中某一点的属性(例如密度)。
Kernel有很多种计算公式,在不同场景下会选择不同的Kernel。DFSPH论文中使用的是Cubic Spline Kernel,计算公式如下:
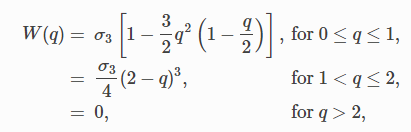
虽然这个式子本身没有特别复杂,但是因为是分段函数,需要执行if语句(if语句在GPU上是开销比较高的),又因为Kernel在每次迭代中都需要执行非常多的次数,所以整体而言消耗了比较多的性能。因而,论文就提出,可以使用Lookup tables的方法对Kernel计算进行优化。
Lookup Tables
Lookup tables方法首先会对函数进行预计算,每隔一定间隔进行采样,并将结果以table形式存储在内存。在之后的运行中,就可以直接从table中查到近似的函数值。
以下面这个线性函数为例:
$$
w(q)=q, q \in [0, 1]
$$
假设采样频率为0.01,那么我们会创建一个表格table[101],并根据如下公式进行初始化
$$
table[i*0.01]=w(i*0.01), i\in[0,100]
$$
在运行时,假设我们需要取 $w(0.054)$ 的值,我们会首先我们会从table中读取,而不再使用原公式进行计算。读取的下标为$i=0.054/0.01=5$,因而最终获取到的值为$table[i*0.01]=0.05$。
在这个例子中,我们可以看到最终获取的结果和精确值之间存在 $(0.054-0.05)/0.05=8$% 的误差。但通过设置足够高的采样频率,我们可以使得计算误差任意的小。在这个示例中我们使用的函数计算很简单,可能体现不出来lookup tables的优势。而其实对于任意复杂的函数,我们都可以使用类似的优化方法,相当于是将原本的任意次加减乘除以及if判断指令,替换为单次内存读取操作。理论上而言,可以取得非常多的性能提升。
实现
于是乎,我就把lookup tables的方法实现在了我GPU加速的流体项目中。不幸的是,性能不仅没有提高,反而有一定幅度的下降。原本的帧率在91~92FPS左右,开启lookup tables优化后,下降到了77~78FPS。
这是为什么呢?经过一番搜寻后,我找到了大致的原因。使用lookup tables后,执行的指令数量确实是大幅下降了,但是内存读取操作却带来了新的问题。内存读取的性能,很大程度上依赖Cache的命中率,如果进行连续读取,Cache命中率可以很高;而在实际应用中,lookup tables通常都是被随机访问的,这引入了大量的Cache Miss。Cache Miss的开销通常远高于省去的加减乘除的开销,最终使得性能反而下降。
在操作系统Linux的讨论邮件中也有涉及这个问题。Linus Torvalds指出:
Lookup tables are only faster in benchmarks, they are almost always slower in real life. You only need to miss in the cache once on the lookup to lose all the time you won on the previous one hundred calls.
为证实这一猜想,我将lookup table的Resolution(也就是table的size)由10000降至了32,此时性能提升到了95~96FPS,略高于原来的性能。但是这么低的Resolution,计算误差是比较大的,再鉴于如此轻微的性能提升,还不如不进行优化。
总结
优化不总是一件好事,理论也不一定能与实践相符。以Linus Torvalds的话收尾:
"Small and simple" is almost always better than the alternatives.